Takeaways from Applying LLM Capabilities to Multiple Conversational Avatars in a VR Pilot Study
Abstract
We present a virtual reality (VR) environment featuring conversational avatars powered by a locally-deployed LLM, integrated with automatic speech recognition (ASR), text-to-speech (TTS), and lip-syncing. Through a pilot study, we explored the effects of three types of avatar status indicators during response generation. Our findings reveal design considerations for improving responsiveness and realism in LLM-driven conversational systems. We also detail two system architectures: one using an LLM-based state machine to control avatar behavior and another integrating retrieval-augmented generation (RAG) for context-grounded responses. Together, these contributions offer practical insights to guide future work in developing task-oriented conversational AI in VR environments.
Short Summary
This report was a part of our efforts to build LLM-powered embodied conversational agents in virtual reality over the Summer of 2024. We conducted a pilot study to explore the effects of avatar status indicators on user experience. The findings and system architecture details are available in the report.
Conversational architecture: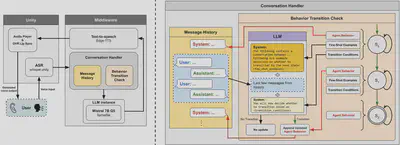
Local Retrieval Augmented Generation (RAG) Architecture: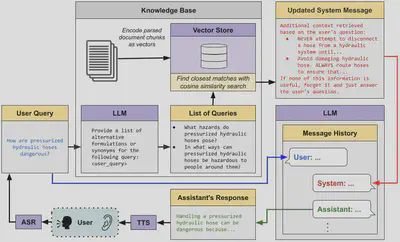
Mykola Maslych
Computer Science PhD Candidate
My research interests include machine learning applied to 3D User interfaces and HCI in general.